We all love watching movies. It’s helpful to use genre as a way to decide what movie to watch, without reading full movie descriptions. But it’s not always easy to identify genre of a movie. Even if one is already identified, it may not be one you agree with. What if there’s a way to identify genre using natural language processing, based on movie plot? Possible applications could be to predict genre when there is none available. Perhaps more common though, is to help identify alternative applicable genres even when there is one identified.
Data Source
Wikipedia movie plots data from Kaggle
(34886 movies)
Code at Github
Here is the github repo for this project: link
Tools Used
Python is used for data acquisition, cleaning and modeling. Specific python libraries used include:
- Modeling: scikit-learn, imbalanced-learn
- Natural language processing:
- NTLK: for sentiment analysis
- Spacy: for text preprocessing and cleaning
Methodology Used
- Genre clean-up:
- Data initially had as many as 2264 genres. Many were either too granular or mis-spellings, so some clean-up is needed. For example, the following were re-mapped as “comedy” genre:
‘comedey’, ‘spoof’, ‘standup’, ‘slapstick’, ‘parody’
- Low-count genre entries were removed (kept top 95%)
- This clean-up process resulted in 12 genres
- Data initially had as many as 2264 genres. Many were either too granular or mis-spellings, so some clean-up is needed. For example, the following were re-mapped as “comedy” genre:
-
Data is randomly sampled from ~30,000 to 10,000 with weights biased towards lower count genres for NLP processing and training speed.
-
Each sentence in a movie plot text is then evaluated for sentiment using NTLK’s vader analyzer. The results are then averaged to be treated as a sentiment feature for that movie entry. (See Jupyter notebook for steps 1-3: (code here) ).
-
Topic modeling is used to reduce the dimensionality of word features to be used in classification training. Before topic modeling can be done, stopwords, punctuations, and entities were removed from the movie plot text. The text is also tokenized and lemmatized.
- Both Non-negative Matrix Factorization (NMF) and Latent Semantic Analysis (LSA) topic modeling were tried. They gave similar results when used in supervised classification modeling later, but I decided to use NMF in the final model because the topics were more interpretable than the LSA ones. THE NMF yielded 25 topics were seemed to be representative of certain genres. For example:
- Topic 1 (Romance): love, fall love, fall, marry, marriage, girl, meet, friend, wedding, story
- Topic 2 (Sci-Fi): alien, planet, spaceship, human, saucer, destroy, space, base, ship, scientist (See Jupyter notebook for steps 5, 6: (code here)).
- For final genre prediction, Random Forest, KNN and Gradient Boost. Random Forest gave slighly better results than GradientBoost so that was chosen as final model. See Jupyter notebook for steps (code here)
Results
- Random Forest yielded the best F1 weighted score of 0.43 on test data set
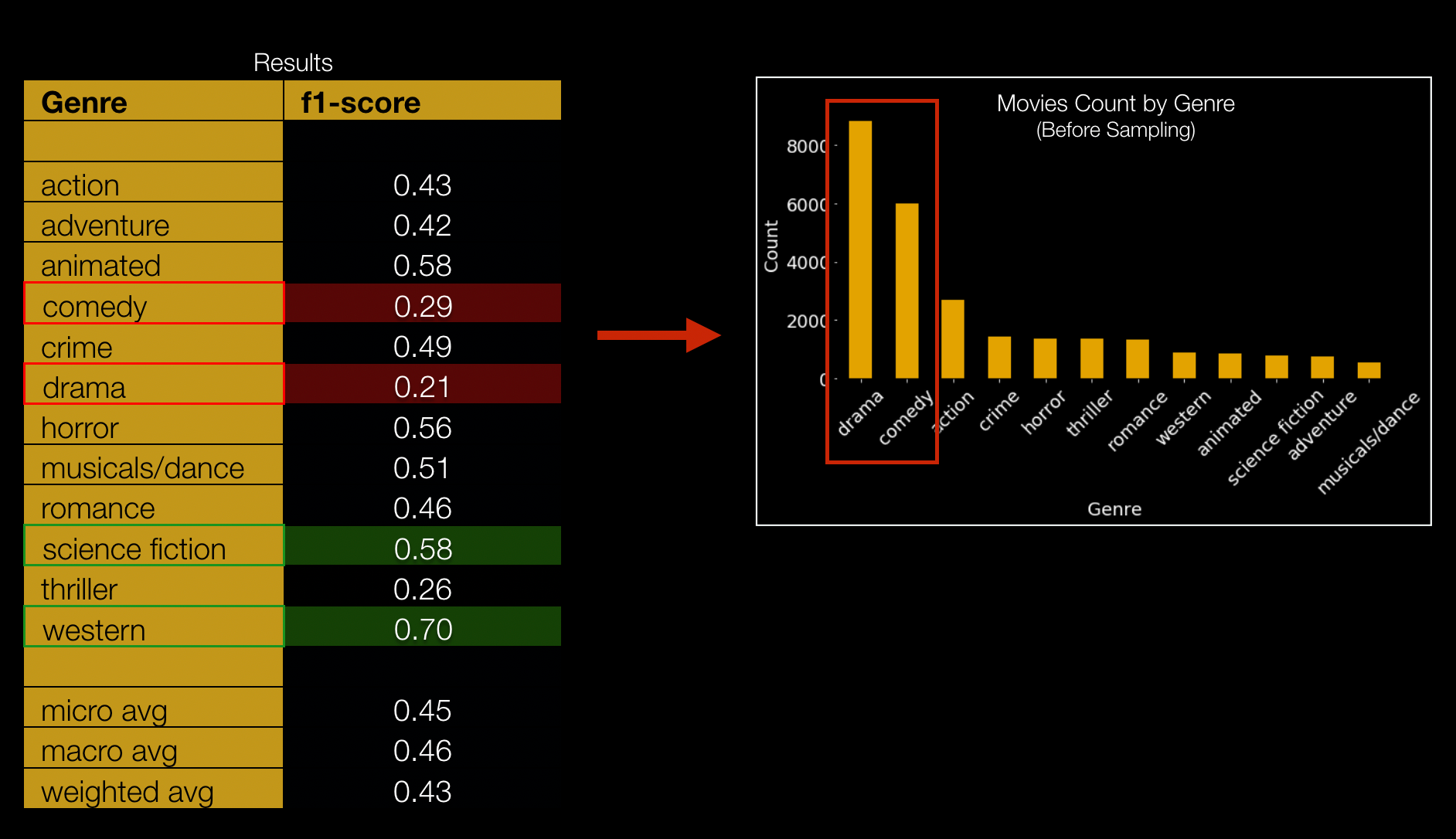
- As seen from the results, “Sci-Fi” and “Western” got best prediction results, but “Drama”, “Comedy” were among the worst. Note drama and comedy also had the largest count of movies, so it looks like there is opportunity to better break down those genres into sub-categories that could yield better prediction results
Conclusions
- Genre categorization impacts the prediction results so more analysis on optimal categorization would be helpful
- Multi-label classification instead of multi-class classification is also a great next step to provide better insights for potential applications as movies often can belong to multiple genres